Crystal 中的并行性


Crystal 在将并行性作为一等公民方面取得了巨大进步。简而言之,您可以在运行时设置工作线程的数量,每个新纤程都将被调度到其中一个线程上运行。Channel 和 select 将无缝地工作。您可以让工作线程之间共享内存,但您可能需要注意一些同步操作以保持状态一致。
这项工作需要付出很多努力,但由于重构、设计讨论以及对并行性工作的尝试,它无疑变得更容易了。无论是否合并,过去的所有工作都作为参考,以便在整个过程中反复核查想法。
在本文中,我们将尝试涵盖所有新的功能描述、设计、我们遇到的挑战以及下一步计划。如果您想立即开始使用它,第一部分就足够了。最终目标是能够使用所有可用的 CPU 能力,而不会对语言造成太大改变。因此,文章末尾可以找到一些挑战和开放性工作。
如何使用它,快速指南
为了利用这些功能,您需要使用 preview_mt 支持构建程序。最终这将成为默认设置,但目前您需要选择加入。
正如您将在本文档中看到的那样,数据可以在工作线程之间共享,但由用户负责避免数据竞争。一些 std-lib 部分仍然需要进行重新设计以避免不安全的行为。
- 使用
-Dpreview_mt构建程序。crystal build -Dpreview_mt main.cr - 运行
./main。(可以选择指定工作线程数量,例如CRYSTAL_WORKERS=4,默认值为4)
API 中第一个顶级变化是,当生成新纤程时,您可以指定是否希望新纤程在同一个工作线程中运行。
spawn same_thread: true do
# ...
end
如果您需要确保某些线程局部状态或调用者是同一个线程,这特别有用。
早期基准测试
本节中显示的基准测试是从 bcardiff/crystal-benchmarks 生成的,使用的是 manastech/benchy,在 c5.2xlarge EC2 实例上运行。
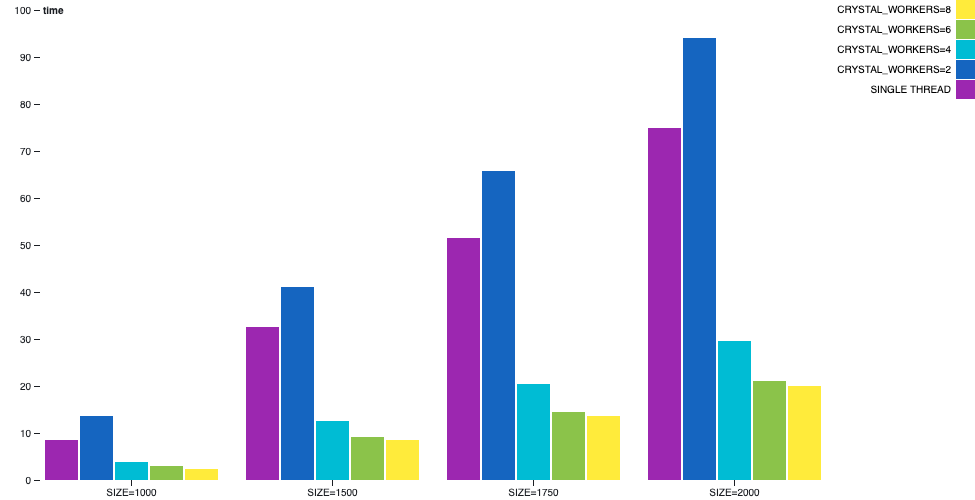
矩阵乘法
矩阵乘法是一个可以并行化的过程,并且可以很好地扩展。它恰好没有 I/O,因此是分析 CPU 绑定场景的良好示例。
在此示例中,当使用多线程编译时,一个工作线程将委派并等待每个坐标的结果完成,而其他工作线程将接收计算请求并进行处理。
当我们将单线程与执行实际计算的 1 个工作线程进行比较时,我们可以看到用户时间有一些增加。由于多线程相对于单线程来说有更重的簿记和同步操作,因此它更慢。但是,只要添加了工作线程,用户就会在性能上获得极大的改进。预计在这种情况下,所有线程都将以最高速度运行。
Hello World HTTP 服务器
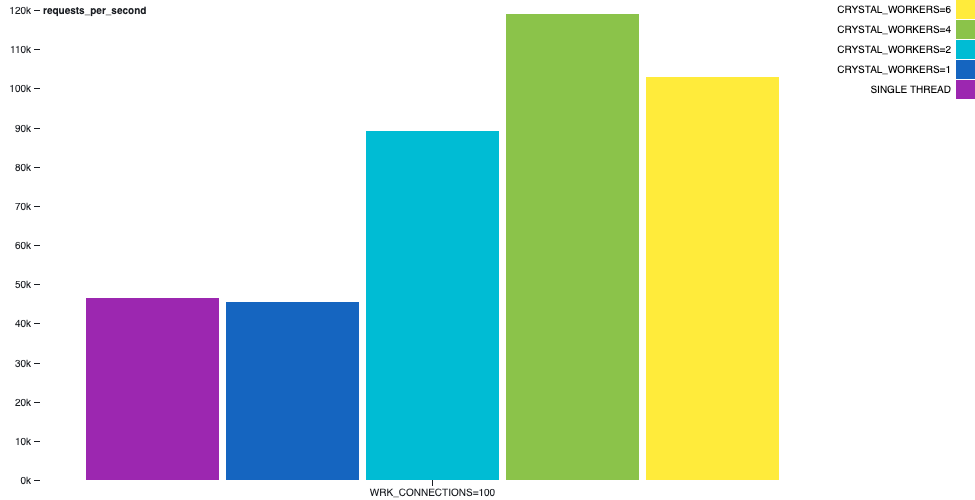
一个通常出现的合成基准测试是一个 HTTP 服务器,它对 GET / 请求回复 hello world。在处理每个请求并构建简短的响应时,通常不需要进行上下文切换,因为在构建响应时会进行 I/O 操作。
例如,在下图中,我们可以描绘 hello-world-http-server 示例的行为方式。wrk 工具在同一台机器上运行,在 30 秒内使用 2 个线程和 100 个连接。吞吐量有一个有趣的增长。
通道素数生成
在 channel-primes 示例中,素数是通过以某种顺序连接多个通道来生成的。第 n 个素数将在打印之前经过 n 个通道。这可以看作是一个病态场景,因为该算法无法以明显的方式进行平衡,并且有大量通信正在进行。
在此示例中,我们可以看到多线程并非万能药。单线程仍然优于多线程。
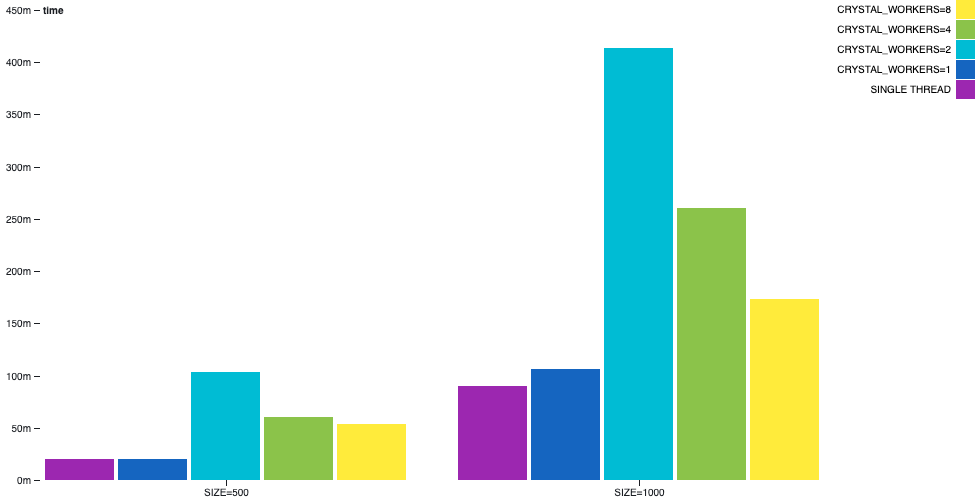
尽管,根据工作线程的数量,墙上时间差异不太明显,但 CPU 时间差异将非常大。
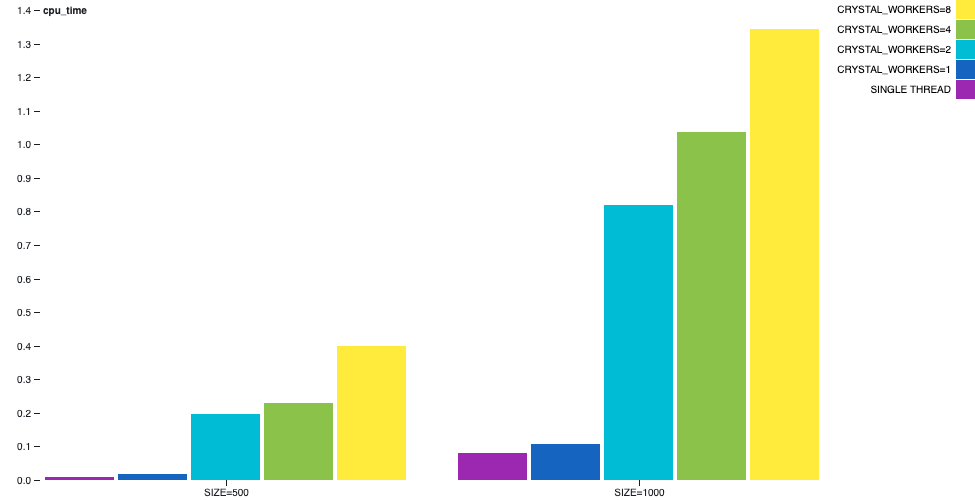
详细描述
我们希望在不改变语言本质的情况下引入对并行性的支持。程序员应该能够以纤程运行、访问数据为单位进行思考,并且在大多数情况下不需要关心代码在哪个线程上运行。这意味着线程和纤程之间共享数据。并且尽可能地将线程隐藏在用户面前。
在此过程中,我们需要处理运行时某些核心方面的内部实现和设计方面的某些更改。我们还需要修复编译器本身的一些问题:有些问题被提取出来并独立提交。最后但并非最不重要的一点是,与启用多线程有关的语言本身的一些健壮性和安全性问题目前正在受到影响。
在单线程模式下,有一个工作线程和一个事件循环。事件循环负责恢复正在等待 I/O 完成的纤程。在多线程模式下,每个工作线程都有自己的事件循环,它们基本上作为先前机制的多个实例工作,但具有一些额外功能。
每个工作线程之间的内存可以共享并且是可变的。这将是许多头痛的根源。您需要通过锁来同步对它们的访问,或者使用一些可以处理并发访问的适当数据结构。
通道能够在不同的工作线程之间发送和接收消息,而无需更改 API,并且应该用作纤程之间通信和同步的主要方法。
select 语句需要额外注意。 select 在不同的通道上注入许多接收器和发送器。只要其中一个满足了 select,其他接收器和发送器就需要被忽略。为此,当纤程被作为发送器或接收器入队到 select 操作中时,会创建一个 SelectContext 来跟踪整个 select 的状态。在 Channel#dequeue_receiver 和 Channel#dequeue_sender 中,如果 select 已经完成,则存在逻辑来跳过它们。
程序启动后,将根据环境变量 CRYSTAL_WORKERS 的值初始化工作线程。每个工作线程都有自己的 Scheduler,其中包含 runnables 队列。
即使在多线程模式下,在工作线程初始化之前,程序也会在很短的时间内仅使用一个工作线程。这种情况发生在初始化某些常量和类变量时。
通过 Scheduler,有一些条件可以保护多线程模式下的状态。尽管队列是独立的,但工作线程需要互相通信以调度新的纤程。如果目标工作线程没有休眠,则可以将新纤程直接入队(注意,队列是从当前工作线程访问的,因此需要进行同步)。如果目标工作线程正在休眠,则使用管道将新纤程发送到执行,通过事件循环唤醒工作线程。在每个工作线程的调度程序中为其创建一个管道。这在 Scheduler#run_loop、Scheduler#send_fiber、Scheduler#enqueue 中进行处理。
哪个工作线程将执行纤程现在由循环轮询方式决定。这种策略可能会在将来根据每个工作线程的负载指标而改变。但我们选择了我们能想到的最简单的逻辑,它将作为将来改进的基线,如果需要。
为了尽可能保持简单,在调度方面,一旦一个 fiber 在工作线程中开始运行,它将永远不会迁移到另一个线程。当然,它可以被挂起和恢复。但我们明确选择从不窃取 fiber 开始。
API 变化
编译多线程程序
目前,在 preview_mt 标志下可以使用支持多线程的编译程序。请确保您使用的是 Crystal 0.31.0(尚未发布)或 master 的本地构建。
$ crystal --version
Crystal 0.31.0
$ crystal build -Dpreview_mt main.cr -o main
在运行时设置工作线程数量
可以通过 CRYSTAL_WORKERS 环境变量自定义工作线程数量。其默认值为 4。
$ ./main # will use 4 workers
$ CRYSTAL_WORKERS=4 ./main
$ CRYSTAL_WORKERS=8 ./main
spawn
默认情况下,使用 spawn 创建的新 fiber 可以自由地在任何工作线程中运行。如果您需要同一个 fiber 在当前工作线程中执行,可以使用 spawn(same_thread: true) { ... }。这对某些使用线程本地存储的 C 库很有用。
Mutex
Mutex 仍然是请求跨越 fiber 的锁的方式。没有实际的 API 更改,但值得注意的是,该行为在多线程模式下仍然有效。有些人可能知道内部 Thread::Mutex 的存在,它是 pthread 的包装器。不建议直接使用 Thread::Mutex,除非您真正了解自己在做什么以及为什么要这样做。使用顶层的 Mutex。
Channel
重新审视了已关闭通道的行为。从现在起,无论是在单线程还是多线程程序中,您都可以在已关闭的通道上执行接收操作,直到所有已发送的消息都被消费掉。这样做是有意义的,因为否则需要对队列和通道状态进行同步。当然,一旦通道关闭,就无法再通过它发送新消息。
Channel(T) 现在表示无缓冲和有缓冲的通道。初始化它们时,分别使用 Channel(T).new 或 Channel(T).new(capacity)。
Fork
在多线程程序中混合 fork 和多线程程序是有问题的。有一些参考资料描述了这种情况下的问题。
在多线程环境下,fork 方法将不可用,并且可能作为公共 API 消失。std-lib 仍然需要 fork 来启动子进程,但这种情况是安全的,因为 fork 后会执行 exec。
另一个可能需要 fork 的场景是将进程守护进程化,但这个故事还需要进一步发展。
锁
在 Crystal::SpinLock 中有一个自旋锁的内部实现,在单线程编译时,它表现为一个空锁。在 Crystal::RWLock 中也有一个 RW-Lock 的内部实现。
这些锁在运行时使用,不希望作为公共 API 使用。但了解它们的存在是件好事。
挑战
我们在进行了几次迭代后才得出了目前的多线程支持设计。其中一些由于性能原因而被丢弃,但其本质和 API 与当前版本类似。其他想法启发我们对进程之间进行一定程度的隔离。设置一些明确的边界可以简化减少锁定和同步的操作。其中一些设计(部分受到 Rust 的影响)会导致进程之间出现可共享和不可共享类型,以及新的闭包类型,以模拟它们是否可以或不能发送到另一个进程。还有其他草稿想法,但我们最终确定了一些与当前程序运行 fiber 访问共享数据的本质更加一致的内容,因为我们找到了一个性能足够高的实现。除了保持运行时工作所需的实现细节之外,还有几个关于语言语义的故事需要进一步发展,但只要您同步共享状态,您就应该是安全的。
通道的生命周期发生了一些变化。简而言之,当一个 fiber 正在等待一个通道时,该 fiber 就不再是可运行的。但现在,等待的通道操作已经有一个指定的内存槽位,消息应该接收在这个槽位中。当要通过该通道发送消息时,该消息将存储在指定的内存槽位中(共享内存 FTW)。最后,被暂停的 fiber 将被重新调度为可运行状态,并且第一个操作将是读取并返回消息。这可以在 Channel#receive_impl 方法中看到。如果等待的 fiber 位于一个处于休眠状态的线程中(没有可运行的 fiber),则用于传递新 fiber 的同一个管道被用来将该 fiber 入队到休眠线程中,唤醒它。
在实现通道和 select 的更改时,我们需要处理一些极端情况,例如 select 在同一个通道上执行发送和接收操作。我们还发现自己在重新思考通道表示的不变式。当我们得出一个与 Go 通道的约束类似的设计时,这对我们来说意义重大。
(..) 除非是一个无缓冲的通道,并且只有一个 goroutine 在使用 select 语句同时阻塞发送和接收,否则 c.sendq 和 c.recvq 中至少有一个为空 (…) 来源
上面描述的通道机制之所以有效,是因为事件循环的设计方式。每个工作线程在 Scheduler#run_loop 中都有自己的事件循环,该循环将从可运行队列中弹出 fiber,如果为空,则将等待直到一个 fiber 通过该工作线程的管道发送过来。这种机制不仅适用于通道,而且适用于一般的 I/O。当要等待一个 I/O 操作时,当前 fiber 将在 IO 内部队列的读取器或写入器队列中保持挂起状态,直到事件在 IO::Evented#evented_close 中完成。同时,工作线程可以继续运行其他 fiber 或处于空闲状态。执行 I/O 的 fiber 由 Scheduler.enqueue 恢复,它将处理与繁忙或空闲线程进行通信的逻辑。
为了与 libevent 集成,我们还需要为每个工作线程初始化一个 Crystal::Event::Base。我们希望 IO 能够直接在工作线程之间共享,并且每个工作线程都需要对一个 Crystal::Event 的引用,该引用包装了 LibEvent2::Event。这些 Crystal::Event 绑定到一个单独的 Crystal::Event::Base。解决方案是每个 IO(通过 IO::Evented)在每个线程的散列索引中都包含事件和等待它的 fiber。当一个线程上完成一个事件时,它将能够只通知该线程的等待 fiber。
@[ThreadLocal] 注解的使用范围并不广泛,并且在 OpenBSD 和其他平台上存在一些已知问题。需要一个内部 Crystal::ThreadLocalValue(T) 类来模拟这种行为,它在 IO 的底层实现中使用。
在某些情况下,常量和类变量是延迟初始化的。我们希望最终改变这种情况,但现在在初始化期间需要一个锁。将该锁放在哪里仍然是一个挑战。因为它不能放在常量中,对吧?编译器熟知的两个内部函数 __crystal_once_init 和 __crystal_once 被引入并用于常量和类变量的延迟初始化函数。
我们提到,初始调度算法是循环调度,没有 fiber 窃取。我们试图对每个工作线程的负载进行度量,但是由于工作线程可以在彼此之间进行通信以委托新的 fiber,因此计算负载将意味着需要更多需要同步的状态。最重要的是,在当前实现中,管道中存在对 fiber 的引用,因此 @runnables 队列的大小并不是一个准确的度量指标。
GC 过去曾支持多线程,但性能不够好。我们最终在上下文切换(读取器)和 GC 收集(写入器)之间实现了一个 RW-Lock。RW-Lock 的实现灵感来自 Concurrency Kit,不使用 Mutex。
不出所料,但值得注意的是,使用多线程支持构建的编译器尚未利用核心。到目前为止,编译器在调试模式下构建程序时使用 fork。因此,由于前面描述的问题,--threads 编译器选项在多线程环境下被忽略。这是一个 fork 的用例,将来将不再支持,需要使用其他结构重新编写。
我们可能的目标是保持单线程模式可用:多线程并不总是更好。这可能会影响分片领域。一个分片是否会被明确限制为在一种模式下工作,而不能在另一种模式下工作,以及如果这样,如何说明这一点,目前尚不清楚。
编译器生成的某些内存表示和低级指令在多线程模式下无法很好地协同工作。至少,我们需要防止段错误以保持语言的健壮性。同样,只要对共享数据的访问是同步的,你就会没事,但这意味着程序员负责,语言不够安全。在以下部分,我们将描述一些场景以及目前解决这些问题的状态。
语言类型安全性
当多个线程并发访问数据结构时,如果没有同步,指令可能会交错并导致意想不到的结果。这个问题并不新鲜,许多语言都存在这个问题。当处理像数组这样的数据结构时,在最坏的情况下,可以考虑对公共 API 进行一些同步。但有时不一致的状态会以更微妙的方式表现出来。
如果语言允许值类型大于可以原子写入的内存量,那么你可能会注意到一些奇怪之处。假设我们有一个共享的 Tuple(Int32, Bool),其中一个线程不断设置值 {0, false},第二个线程设置值 {1, true},而第三个线程将读取该值。由于指令交错,最后一个线程会偶尔发现值 {1, false} 和 {0, true}。这里没有发生不安全的事情,它们是 Tuple(Int32, Bool) 的可能值,但奇怪的是,从未写入的值可以被读取。许多具有任意大小值类型的语言通常表现出这种问题。
在 Crystal 中,值类型和引用类型之间的联合表示为一个类型 ID 和值的元组。一个 Int32 | AClass 的联合保证不会具有 nil 值。但是,由于交错,nil 的表示可能会出现,并且会发生空指针异常(在这种情况下为段错误)。
关于数组,可能会发生类似的事情。一个引用类型数组(没有 nil 作为值)会导致段错误,因为一个线程可能会在另一个线程取消引用最后一个项目时删除一个项目。删除项目会在内存中写入一个零,以便 GC 可以声明该内存,但零地址不是可以取消引用的值。
有一些想法可以以不同的方式执行联合的代码生成。其中一种方法已经可以工作,但代价是增加程序的内存占用量和二进制大小。我们希望迭代其他方案,并在选择方案之前进行比较。目前你需要知道,出现在类变量、实例变量、常量或闭包变量中的共享联合是不安全的(但将变得安全)。
为了处理数组的不安全行为,需要讨论人们可能想要在共享可变数据结构中获得的不同方法和保证。最强的保证类似于序列化其访问(想想每个方法周围的互斥锁);较弱的保证是访问没有序列化,但始终会导致一致的状态(想想每次调用都会产生一致的最终状态,但没有保证使用哪个);最后,是允许交错状态操作的空保证。
在选择保证级别后,我们需要为它找到一种算法。到目前为止,我们已经围绕着较弱的一种保证实现了代码。但这需要与 GC 进行一些集成。这种集成目前是一个瓶颈,我们还在不断迭代。目前你需要知道,共享数组是不安全的,除非手动进行同步。
在数组中发现的挑战出现在每个指针操作中。指针是不安全的,虽然我们在处理数组的代码,但我们确实希望在语言中拥有安全/不安全部分来指导审查过程。还有其他结构,比如双端队列,也存在同样的问题。
下一步
虽然在我们可以宣称多线程模式是语言的一等公民之前,还有一些待办事项,但在运行时进行此更新无疑是一个巨大的进步。我们希望收集反馈并不断迭代,以便在接下来的几个版本中,我们可以从 preview_mt 中移除 preview。
我们能够做到这一切,要感谢 84codes 和其他所有 赞助商 的持续支持。对我们来说,通过捐赠持续获得支持至关重要,这样我们才能保持这种开发速度。 OpenCollective 和 Bountysource 是两个可用的渠道。如果你想成为直接赞助商或寻找其他支持 Crystal 的方法,请联系 crystal@manas.tech。我们提前感谢你!